What to do if Semonto could not monitor your website
Does Semonto return an HTTP 403 status code or the message “Blocked by robots.txt” when you are trying to monitor your website? This is what you can do about it.

Contents
Semonto visits the pages of your website to check whether they are accessible and functioning as they should. To do this, our software frequently connects to your server and uses techniques like crawling to run tests and detect issues like broken links. But if your website refuses to let our software in, we cannot monitor your website. Let’s discuss the different possible causes so that you can find a way to fix your situation.
Possibility 1: Semonto is blocked by a firewall
If you have a firewall, it could be possible that your firewall is blocking traffic from Semonto to your website. Please ensure our Semonto IP addresses can connect to your server. You can test the connection from Semonto to your website by using our free reachabilty test.
What you can do: whitelist our IP addresses
We always monitor from a fixed list of IP addresses (if they do change, we will let you know). You can whitelist our IP addresses to decrease the chance of them being blocked by your firewall.
This is our list of IP addresses in multiple formats:
Possibility 2: Semonto is blocked by robots.txt
As a website owner, you can control which information on your website is indexed by search engines like Google. There can be certain pages that you do not want not appear in the search results. For example: pages with very little content or with sensitive information. One way to tell crawlers to ignore a part of your website is by using a robots.txt file. That is a simple text file that tells the web crawlerwhich parts of the site it is allowed to visit and which parts it should avoid. The problem is that not only search engines use crawlers. Website monitors use them too. So if you close the door for our crawlers, we cannot monitor your pages and Semonto will return “Blocked by robots.txt”.
How does robots.txt work?
Our crawler will first read your robots.txt to see whether it is allowed to visit your website. The robots.txt rules contain two parts:
User-agent: which crawler you are defining a rule for
Disallow: which parts of the website the crawler is not allowed to visitFor example, if you do not want Googlebot to crawl your private folder, you could put this in your robots.txt:
User-agent: Googlebot
Disallow: /private/Read more about robots.txt syntax here.
What is the Semonto user agent?
The user agent of Semonto is:
Mozilla/5.0 (compatible; Semonto/2.0; +https://semonto.com/monitoring; websiteMonitoring)Why does Semonto get blocked by robots.txt?
If Semonto is being blocked, chances are that you have blocked all crawlers. That would look something like this in your robots.txt file:
User-agent: *This * means that you are blocking every robot.
Also, make sure to check what is being mentioned in the Disallow-field, because those pages or folders will possibly be skipped by Semonto and could affect your results.
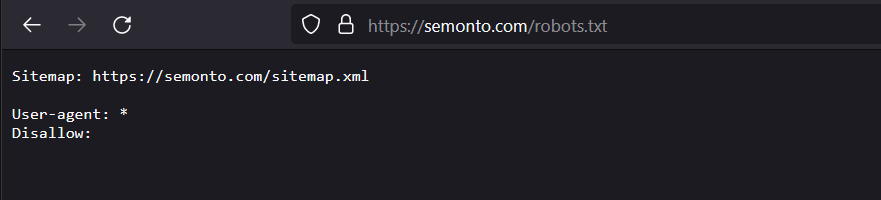
Where can I see my robots.txt file?
Open your browser and type your URL, followed by /robots.txt. If you have a robots.txt file, it will appear. For example, the robots.txt file for Semonto is https://semonto.com/robots.txt
How to fix it
Changing the robots.txt file is usually done by your web developer. Ask them for assistance, or feel free to reach out to us for help.
There are 2 fixes you can try:
- Allow all crawlers Delete the existing rule altogether, if you want to allow all crawlers from now on.
- Allow Semonto Add another rule and place it before the existing rule. The rule should specify Semonto as an allowed user-agent and leave the Disallow-field empty:
User-agent: Semonto
Disallow:With this rule you are saying that Semonto is allowed to visit all pages of your website.
Possibility 3: status code HTTP 403
If Semonto did not get blocked by the robots.txt file, it will go on to check the status of your website. It does so by requesting the first page and then checking the returned status code. A status code is a message that your server sends to your browser to explain if your request was successful. You are probably familiar with the most common status codes:
- HTTP 200 means that everything is OK.
- HTTP 404 means that the requested resource could not be found.
HTTP 403 means “Access forbidden”. This code indicates that we do not have permission to visit the resource. Semonto can return this message for an entire website or for a specific page. The message is the same in both cases: “We were not allowed to go there.”
Read more about the most common status codes here.
What are the probable causes?
- Log-in required: On some websites, you need a login and password to visit certain pages. Since Semonto cannot log in for you, it is normal for you to get an HTTP 403 for those pages.
- IP limitations: As explained in the first possibility, access to some parts of a website or to the entire website can be restricted based on the IP address or even user-agent of the requester.
What are possible solutions?
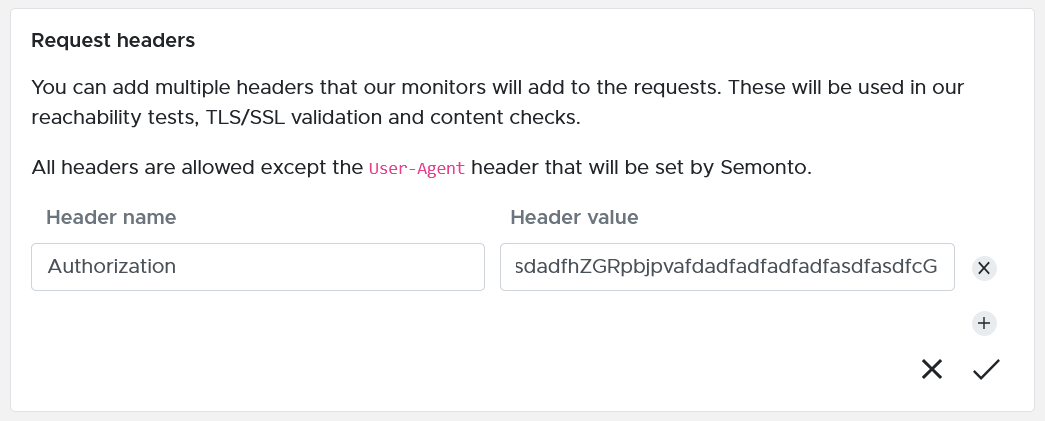
- For reachability, SSL and content checks: You can add a custom header to the requests used by our monitors. This custom header will be used in our reachability tests, TLS/SSL validation and content checks. Adding more information to the request can help you bypass authorization restrictions. You can add, for example, an authorization token or an API-key to the header.
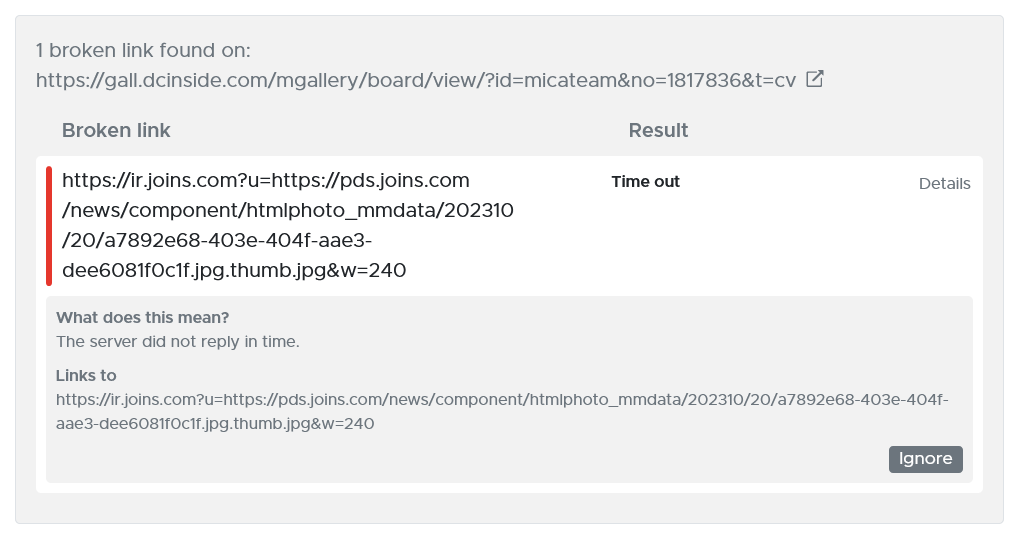
- For broken links: If you do not want to be notified of broken links scans on pages you have no access to, you can hit the “ignore” button in the broken links results.
Possibility 4: blocked by Cloudflare
Sometimes an HTTP 403 is caused by strict page rules settings in Cloudflare, a Content Delivery Network. We have addressed this issue in a separate article about Cloudflare.
Possibility 5: blocked by robots metatags
In the same way a robots.txt file can tell crawlers that they are not allowed (see earlier in this article), robots metatags can also be used. While a robot.txt file is placed in the root directory of a website, robots meta tags are HTML elements that are placed within the
section of individual web pages. They provide instructions specific to the page on which they are placed, overriding any conflicting rules in the robots.txt file.They are used for more detailed instructions, allowing you to specify how a single page should be treated by web crawlers.Signs that Semonto is being blocked by robots metatags
- If you are using Semonto to scan your website for broken links and the results are incomplete, that could mean that we have skipped certain pages because we were not allowed to scan them. In that case: check the robot metatags for that page and edit them if needed. For example: your website has 200 pages and Semonto only scanned 198 pages.
- If Semonto does not report a known broken link, chances are that you have blocked Semonto from that page. If we are not allowed to scan a page, we cannot notify you of any broken links on that page. Solution: check the robots metatags for that page and edit them if needed.
Why does Semonto get blocked by robots metatags?
If Semonto is being blocked, chances are that you have blocked all crawlers. That would look something like this in your robots.txt metatags:
<meta name="robots" content="noindex, nofollow">How can I fix it?
Delete the robots metatags or change them to “index, follow”.
Let us know if you need any help
Have you found what you were looking for in this article? If not, feel free to reach out. We love to help you with any issue you are running into.
Related guides

QuickStart Beginner’s Guide to Semonto

How to Check Your Website for Broken Links With Semonto

How to Check Your Website for Mixed Content

How to monitor your TLS/SSL certificates

How to monitor your website
